
- Meek models, or those that are trained on smaller, fixed budgets, are poised to close the gap on larger, more costly models.
- When examining training loss difference, the research scientists found that as the top model faces decreasing returns to compute scaling, the gap between high- and low-budget AI systems eventually shrinks.
- These findings could open the door to more companies seeking to innovate with AI, especially as technology advances.
If there’s one thing that’s dimmed AI optimism in recent years, it’s the wider understanding of its enormous cost. An assessment by MIT Technology Review estimated that training the OpenAI GPT large language model (LLM) cost over $100 million and consumed 50 gigawatt-hours of energy, enough to power the entire city of San Francisco for three days.
As AI models scale, they require more compute power and energy to run them, raising questions about where this economic and environmental trajectory is taking us.
Get IDE insights delivered to your inbox. Subscribe to the IDE Newsletter →
Meek models vs. state-of-the-art AI models
Research scientists from the MIT Initiative on the Digital Economy are examining the assumption that larger AI models will continue to deliver better outcomes and have more capabilities than smaller models.
The paper, Meek Models Shall Inherit the Earth, by Hans Gundlach, Jayson Lynch and Neil Thompson, asserts that “AI training is stretching the limits of data, computation, and energy, and continued scaling may slow down in the near future.”
Why?
When the researchers studied the difference in performance of “meek models”—AI systems trained to run with modest, fixed budgets—and larger “state-of-the-art models,” they found that as the top model scaled, it had decreasing returns on additional investment. Eventually, the gap between high- and low-budget AI systems shrank.
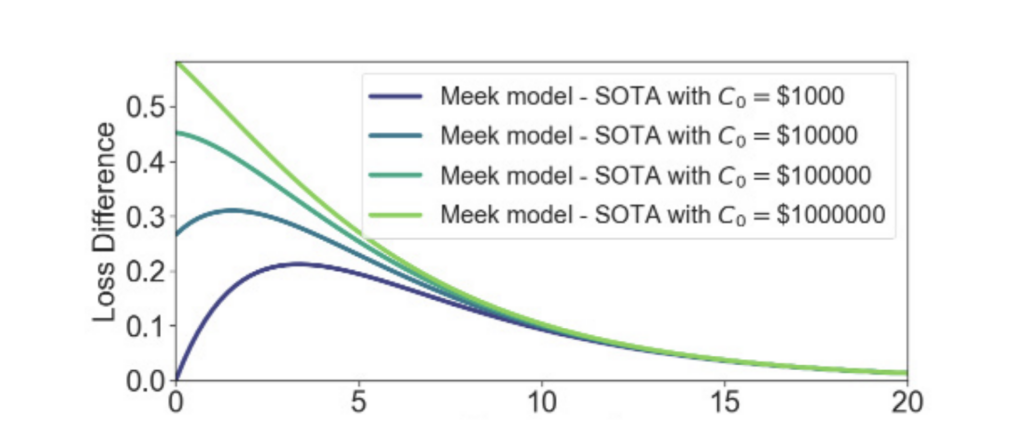
They found that meek models likely benefit from improvements in AI algorithms and hardware, opening the door for lower-cost AI models to steadily close the capability gap with more expensive state-of-the-art systems.
“Hence, models trained or run with limited resources, ‘meek’ models, will have more comparable performance to state-of-the-art models,” the study found.
The cost and energy advantages of lower-budget models
This is undoubtedly welcome news for companies that lack the resources to train ever-larger AI models. According to consulting firm McKinsey & Co.’s State of AI in 2025 survey, only one in three companies are scaling their AI programs across their organizations. Larger companies, considered those with over $5 billion in annual revenue, are the ones more likely to have reached the scaling phase.
As meek models and small language models in general deliver increasingly competitive performance, building and deploying powerful systems should become a more cost-efficient infrastructure effort. As such, it could also offer a more democratic route to scaling AI capabilities.
Such models also could lead to significant electricity savings, which would be a valuable innovation for individual companies and the countries they operate in.
AI energy efficiency on the rise
The research team that published the paper is part of the IDE research group AI, Quantum and Beyond. Among its research is examining the computational and energy costs of AI and the capabilities of more efficient models.
They’ve found that advances in both algorithmic efficiency and hardware capabilities have increased the energy efficiency of AI overall.
IDE Research Lead and MIT CSAIL researcher, Neil Thompson, coined the term “negaflops” to define this phenomena. Just like a “negawatt” is energy saved via efficiency, a “negaflop” is an AI computing operation (or flop) that doesn’t need to be performed due to algorithmic improvements. These increases in efficiency lead to more capable AI models without a proportional increase in computing power or environmental impact.
“If you need to use a really powerful model today to complete your task, in just a few years, you might be able to use a significantly smaller model to do the same thing, which would carry much less environmental burden,” Thompson told MIT News. “Making these models more efficient is the single-most important thing you can do to reduce the environmental costs of AI.”
As noted, meek models with lower computational budgets can benefit from these advancements, doing more with less. As a result, meek models hold potential for innovation and could become a more significant part of the AI ecosystem. When AI models have smaller training budgets, lower inference costs, and reduced energy consumption, it makes them more accessible to more businesses, not just those with big budgets.
Read the full working paper: Meek Models Shall Inherit the Earth
Read our research brief on Meek Models Shall Inherit the Earth.
Jennifer Zaino is a contributing writer and editor to the MIT Initiative on the Digital Economy.